# Umgang mit Dateien
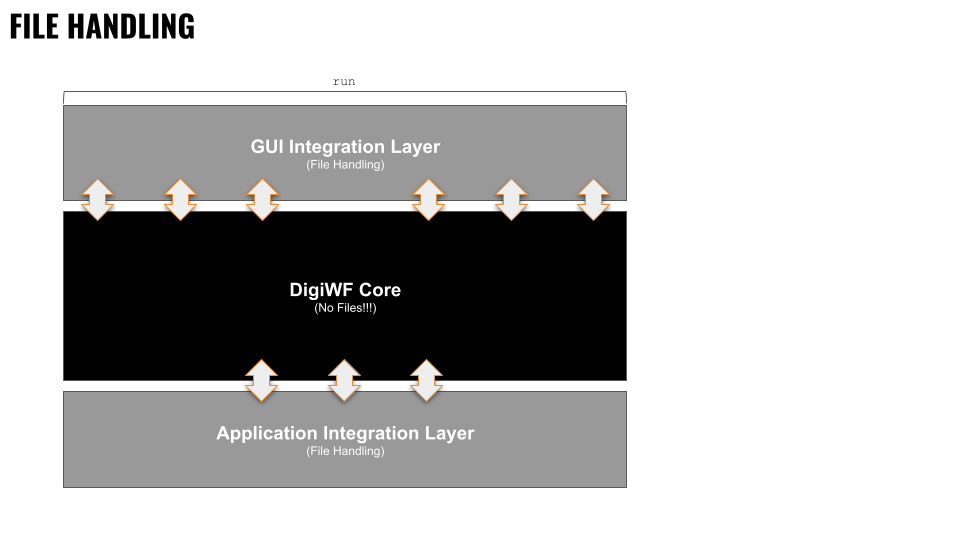
Der Umgang mit Dateien stellt eine Prozess- und Integrationsplattform naturgemäß vor Herausforderungen. Dateien können sehr groß sein oder in großer Anzahl auftreten und stellen somit ein potenzielles Ressourcenproblem dar. Deshalb werden bei DigiWf grundsätzlich keine Dateien in den Speicher geladen oder durch den Prozess geschleift. Das File Handling findet in den Integrations Layern (entweder GUI oder Backend) statt.
Ein grundlegendes Element bei der Behandlung von Dateien (unabhängig davon, ob sie über die GUI oder angebundene Backend
Komponenten in das System gelangen) ist der Dateispeicher. Im Fall von DigiWF ist das ein S3-Service. Hier kann eine
Cloudlösung wie AWS oder ein on-prem Dienst verwendet werden. Die Kommunikation mit dem Dienst an sich wird über eine
generisch gültige Schnittstelle abstrahiert.
Grundsätzlich ist es möglich (und bei mehrfacher Nutzung der Plattform empfehlenswert), mehr als einen S3 Bucket als
Dateispeicher bereitzustellen. Allerdings nicht im selben S3 Service - hier gibt es eine 1:1 Beziehung zwischen
Service und S3 Bucket. Trotzdem kann - je nach Fachlichkeit - hier nach Domäne, Prozess oder Abteilung ein
eigener S3 Bucket mit einem eigenen S3 Service an die Plattform angebunden werden. Das heißt bei einer größeren
Installation (beispielsweise unternehmensweit) wird man in der Regel n S3 Services angebunden haben.
# Datei Handling im Application Integration Layer
Klassische Fälle, in denen Dateien im Application Integration Layer behandelt werden müssen, sind:
- E-Mail (mit Anhängen)
- Datei- und Aktenablage in einem Document Management System
- Erzeugen von Dateien, wie beispielsweise PDF Generierung
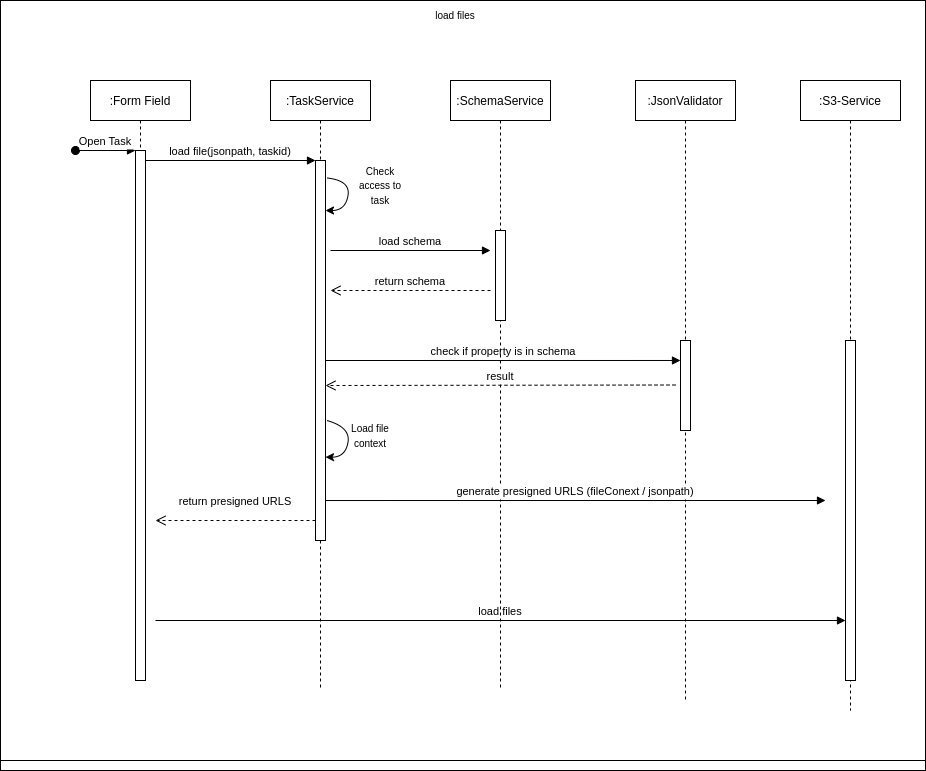
# Eingehende Dateien
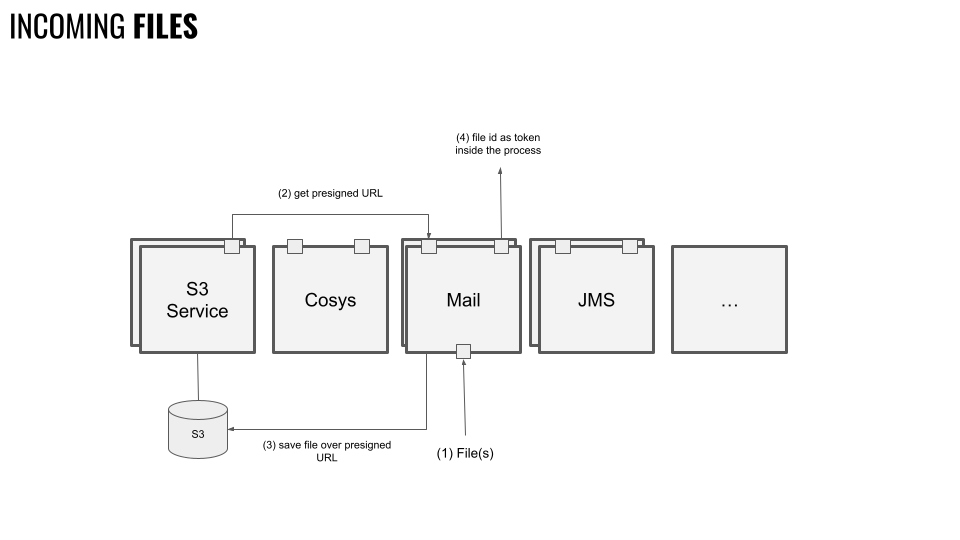
In der Abbildung oben ist zu sehen, wie mit eingehenden Dateien umgegangen wird.
- Eine Datei wird erzeugt oder von außen empfangen.
- Um die Dateien zu speichern, wird eine
presigned URL[1] amS3 Servicefür die Speicherung abgefragt und erzeugt. Einepresigned URList eine zeitlich begrenzt gültige URL, die für eine bestimmte Operation (z.B.POST,PUT, usw.) verwendet werden kann, um Dateien direkt an einenS3 Bucketzu schicken, ohne eingeloggt sein zu müssen. Wie lange eine solche URL gültig ist, kann eingestellt werden. Für den hier dargestellten Anwendungsfall funktionieren auch sehr kurze Gültigkeitszeiträume, da es sich hier um eine rein maschinelle Verarbeitung handelt. Zusätzlich zur URL wird an dieser Stelle noch eine Referenz- oder Datei-ID erzeugt und zurückgegeben. - Mit der URL wird die Datei nun direkt in den S3 Speicher geschrieben. Das geht ohne Umweg über einen weiteren Service.
- Die Dateireferenz wird über den
Event Busan den Prozess übergeben. Ab dieser Stelle ist der Prozess dafür verantwortlich, diese Datei-ID sorgsam aufzubewahren, denn nur mit dieser Referenz kann man die Datei noch über denS3 Servicefinden und entsprechend laden.
# Ausgehende Dateien
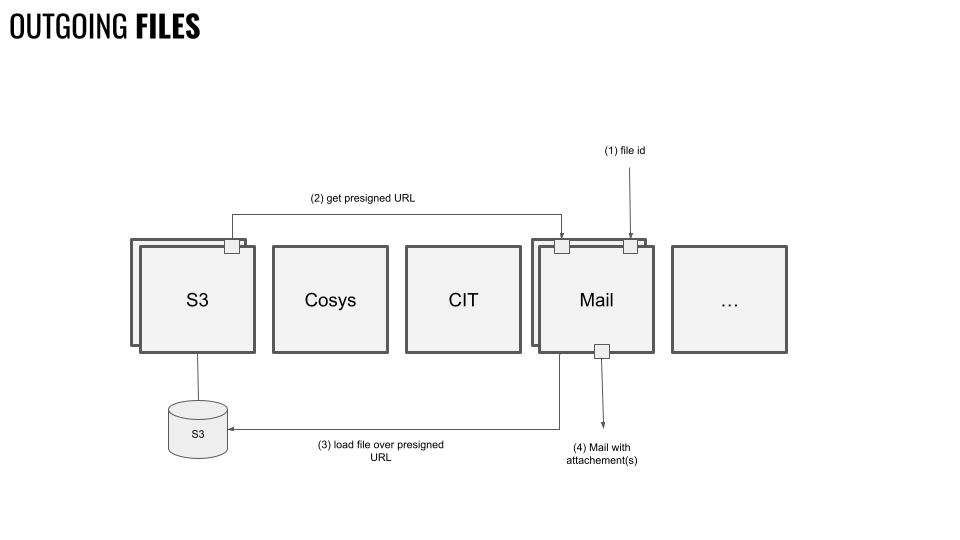
In der Abbildung oben ist zu sehen, wie mit ausgehenden Dateien umgegangen wird.
- Grundvoraussetzung, um eine Datei (oder einen ganzen Ordner) aus dem
S3 Bucketzu holen, ist die Referenz- oder Datei-ID. Will man mehrere Dateien/Ordner laden - und beispielsweise an eine E-Mail anhängen - so werden auch entsprechend viele Referenz IDs benötigt. D.h. die Kardinalität zwischen Datei/Ordner und Referenz ID ist immer 1:1. - Mit der Referenz-ID kann am
S3 Serviceeinepresigned URLfür die OperationGETerfragt werden. Auch hier gilt: Für jede Datei wird eine eigenepresigned URLbenötigt. - Mit der
presigned URLkann wiederum die Datei direkt aus demS3 Bucketgeladen werden. - Die Datei(en) werden an die Mail gehängt und verschickt.
WARNING
Es ist übrigens davon abzuraten, eine presigned URL direkt herauszugeben (beispielsweise per Mail zu verschicken). Wie oben beschrieben, ist eine solche URL nur eine bestimmte Zeit gültig. D.h. wenn dieser Zeitraum abgelaufen ist, dann kann über die URL nicht mehr auf die Datei zugegriffen werden. Wenn dann auch noch die Prozessinstanz beendet wurde, hat man auch nicht mehr so einfach Zugriff auf die Referenz ID.
# Datei Handling im GUI Integration Layer
Dateien kommen natürlich nicht nur aus angebundenen Verfahren, sondern können auch über die grafische Benutzeroberfläche
ins System gelangen. Auch hier wird das File Handling über den S3 Service abgewickelt. Wichtig ist hierbei, dass die
Kommunikation nicht - wie bei den Integrationsartefakten - über den Event Bus erfolgt, sondern per REST Aufruf, da
die Oberflächenkomponenten keinen direkten Zugang zum Event Bus haben.
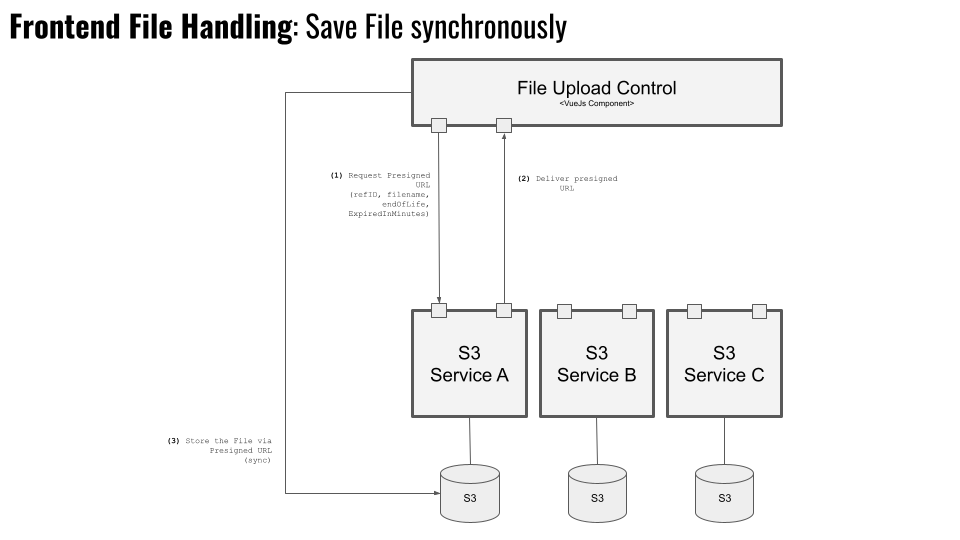
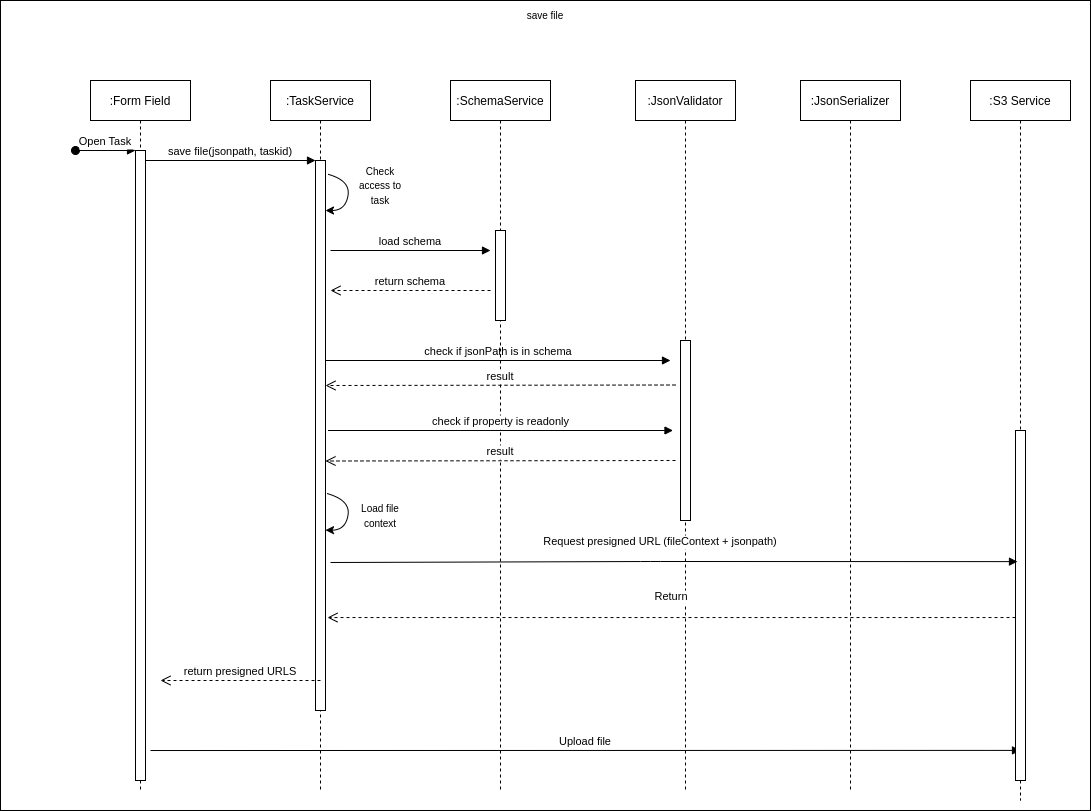
Hier wird beschrieben, wie aus der Formularkomponente File Upload Control heraus eine Datei gespeichert wird. Der Weg
ist aber prinzipiell auch für eigene Formulare oder andere Oberflächen nutzbar.
- Es wird eine
presigned URLamS3 Serviceangefragt. Dazu werden folgende Parameter übergeben:refIDDie Referenz, unter der die Datei später abgerufen werden kannfilenameDer Name der Datei, die gespeichert werden soll.endOfLifeEs kann ein Löschdatum mitgegeben werden. Zu diesem Zeitpunkt wird die Datei dann automatisch aus dem S3 Speicher gelöscht. Das ist vor allem dann sinnvoll, wenn Daten nur eine bestimmte Zeit aufbewahrt werden dürfen.expiredInMinutesDie Zeitspanne in Minuten, für die der Link gültig ist. Nach Ablauf dieser Zeit kann er nicht mehr verwendet werden.
- Der
S3 Serviceerzeugt über den S3 Storage eine entsprechendepresigned URL. Was dort genau passiert, ist im Sequenzdiagramm unten ersichtlich. Diese URL wird an dasFile Upload Controlzurückgegeben. - Über die
presigned URLkann nun die Oberflächenkomponente die Datei direkt an den S3 Storage übergeben.
Wenn man mehr als eine Datei speichern will, so muss dieser Vorgang natürlich entsprechend oft wiederholt werden.
# Authorization beim Umgang mit Dateien aus dem Frontend
Während in der Integrationsschicht relativ klar ist, wer auf welche Datei zugreifen kann, ist dies im Frontend deutlich schwieriger zu entscheiden, da hier potenziell erst einmal jeder auf die Schnittstelle zugreifen kann.
siehe https://docs.aws.amazon.com/AmazonS3/latest/userguide/using-presigned-url.html ↩︎